关于 CPU 的缓存的证明和应用
1. 证明:
首先,我们都知道现在的 CPU 多核技术,同时会有三级缓存(L1,L2,L3 ),如图:
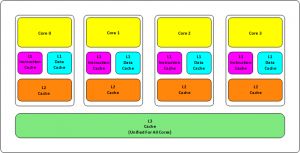
缓存基本上来说就是把后面的数据加载到离自己近的地方,对于 CPU 来说,是一个字节一个字节的加载数据的吗?其实不是的,一般来说都是要一块一块的加载的,对于这样的一块一块的数据单位,我们叫做“Cache Line”,中文翻译:缓存行,一般来说,一个主流的 CPU 的 Cache Line 是 64 Bytes,也就是 8 个 64 位的整型,这就是 CPU 从内存中捞数据上来的最小数据单位。那么这个如何证明呢?
package cn.bridgeli.demo;
import java.util.concurrent.CountDownLatch;
/**
* @author BridgeLi
* @date 2021/11/29 20:41
*/
public class CacheLineTest {
private static long loop = 1_0000_0000L;
private static class T {
// private volatile long x1, x2, x3, x4, x5, x6, x7;
private volatile long x = 0L;
// private volatile long x8, x9, x10, x11, x12, x13, x14;
}
private static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(2);
Thread t1 = new Thread(() -> {
for (long i = 0; i < loop; i++) {
arr[0].x = i;
}
countDownLatch.countDown();
}, "t1");
Thread t2 = new Thread(() -> {
for (long i = 0; i < loop; i++) {
arr[1].x = i;
}
countDownLatch.countDown();
}, "t2");
long currentTimeMillis = System.currentTimeMillis();
t1.start();
t2.start();
countDownLatch.await();
System.out.println(System.currentTimeMillis() - currentTimeMillis);
}
}
我们定义了一个长度为 2 的数组,数组中的元素是 T 类型,T 有一个属性 x,我们同时启动两个线程分别给第一个元素和第二个元素中的 x 复制从 0 到一亿减 1,这个时候我们测试他耗时多少,不同的电脑配置肯定是不同的,我的电脑大概是四千多毫秒,然后我们把 T 对象中属性 x 前后各被注释调的一行打开再跑一次看看,变成了大概 700 毫秒,相差整整 6 倍!这是为何?
其实很简单,这就是我们的 Cache Line 在起作用。第一次,x 属性前后没有属性,然后我们数组中第一个元素的 x 属性和第二个元素的 x 属性,很有可能在同一个缓存行,所以我们的 CPU 在加载数据的时候会把他们一起加载到 CPU 的缓存行中,也就是第一个核心的缓存行中有数组中第一个元素的 x 属性,同时也会有第二个元素的 x 属性,第二个核心也是一样的,因为他们在同一个缓存行,会被同时加载。然后此时 t1 线程对下标为 0 的元素的 x 属性做了修改,为了保证数据一致性,那么其他 CPU 核心加载的缓存行,必须通知他们失效,重新加载,这叫缓存一致性算法,inter 上叫 mesi。那么如果我们在 x 的属性前后分别加 8 个 64 位的属性呢?
我们知道了缓存行的大小是 64 字节,也就是刚好是 8 个 64 位的 long 类型,所以这样一来 x 属性前面有 56 字节数据,后面同样也有 56 字节数据,这样数组中第一个元素的 x 属性和第二个元素的 x 属性,必定不在同一个缓存行中,那么 CPU 在加载数据的时候,第一个元素的 x 属性和第二个元素的 x 属性,必定不会同时加载到一个同一个核心中,然后此时 t1 线程对下标为 0 的元素的 x 属性修改,就不用通知其他 CPU 的核心,把缓存失效,这样多个核心就不会相互影响了,从而提高了性能。
2. 应用:
实际工作中,真的有这么干的吗?还真有,有一个框架叫 Disruptor,是一个单机 MQ,就以高性能著称,里面就有这种写法。
依赖:
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.4.4</version>
</dependency>
com.lmax.disruptor.RingBufferPad 类什么事都没干,里面就是 7 个long,在这个框架中,这样的例子数不胜数。
3. 使用注解
如果我们的代码中,有很多类似的代码,其实挺难理解的,所以 JDK8 新增了一个注解:@sun.misc.Contended,对某字段加上该注解则表示该字段会单独占用一个缓存行,不过需要注意的是:JVM 添加 -XX:-RestrictContended 参数后 @sun.misc.Contended 注解才有效
作 者: BridgeLi,https://www.bridgeli.cn
原文链接:http://www.bridgeli.cn/archives/731
版权声明:非特殊声明均为本站原创作品,转载时请注明作者和原文链接。
近期评论